Istio 运维实战
前言
通过将微服务中原本在 SDK 中实现的应用流量管理、可见性、通信安全等服务治理能力下放到一个专门的“服务网格”基础设施中,Istio 解开了微服务的服务治理需求和业务逻辑之间的代码、编译、部署时机等的耦合,让微服务真正做到了承诺的“按需选择开发语言”,“独立部署升级”等能力,提升了微服务开发和部署的敏捷性,释放了微服务模式的生产力。
然而,“服务网格”这一基础设施的引入也给整个微服务的运维技术栈带来了新的挑战。对于运维同学来说,Istio 和 Envoy 的运维存在着较陡的学习曲线。腾讯云 TCM(Tencent Cloud Mesh)团队是业内最早一批接触服务网格技术的人员之一,有着大量 Istio/Envoy 故障排查和运维经验。本电子书记录了腾讯云 TCM 团队从大量实际案例中总结出来的 Istio 运维经验,以及使用 Istio 的最佳实践,希望对大家有所帮助。
1 - Istio 调试指南
如何快速分析处理服务网格系统自身的问题
服务网格为微服务提供了一个服务通信的基础设施层,统一为上层的微服务提供了服务发现,负载均衡,重试,断路等基础通信功能,以及服务路由,灰度发布,Chaos 测试等高级管控功能。
服务网格的引入大大降低了个微服务应用的开发难度,让微服务应用开发人员不再需要花费大量时间用于保障底层通讯的正确性上,而是重点关注于产生用户价值的业务需求。
然而由于微服务架构的分布式架构带来的复杂度并未从系统中消失,而是从各个微服务应用中转移到了服务网格中。由服务网格对所有微服务应用的通讯进行统一控制,好处是可以保证整个系统中分布式通讯策略的一致性,并可以方便地进行集中管控。
除微服务之间分布式调用的复杂度之外,服务网格在底层通讯和微服务应用之间引入了新的抽象层,为系统引入了一些额外的复杂度。在此情况下,如果服务网格自身出现故障,将对上层的微服务应用带来灾难性的影响。
当系统中各微服务应用之间的通讯出现异常时,我们可以通过服务网格提供的分布式调用跟踪,故障注入,服务路由等手段快速进行分析和处理。但如果服务网格系统自身出现问题的话,我们如何才能快速进行分析处理呢?
1.1 - Envoy 日志调试指南
1. 问题背景
这是使用 Istio 最常见的困境:在微服务中引入 Envoy 作为代理后,当流量访问和预期行为不符时,用户很难快速确定问题是出在哪个环节。客户端收到的异常响应,诸如 403、404、503 或者连接中断等,可能是链路中任一 Sidecar 执行流量管控的结果, 但也有可能是来自某个服务的合理逻辑响应。
特别的,当 Service Mesh 系统的维护者和应用程序的开发者来自不同的团队时,问题尤为凸显。
在 Mesh 中引入全链路跟踪系统,可以解决部分问题,我们可以知道请求到达了哪些工作负载,但是对于中断的异常请求,我们仍然很难确定原因。 因为本着最大透明化(Maximize Transparency)的设计目标,Istio 的遥测系统会尽量屏蔽掉 Sidecar 的存在。另一方面,用户自行维护一套全链路跟踪系统成本也很高,受限于遥测采样率和有限的协议支持,我们通常无法采集所有链路数据。
幸运的是,Envoy 本身可以记录流量的信息,本文主要介绍如何利用 Envoy 日志,对类似问题进行定位。
2. Envoy 流量模型
我们先看看 Envoy 的流量模型:
- 监听,接受连接
- 根据用户流量操纵规则,进行流量特征识别
- 进行流量操纵,如负载均衡,转发,拒绝等
在以上流程中, Envoy 接受请求流量叫做 Downstream,Envoy 发出请求流量叫做 Upstream。在处理 Downstream 和 Upstream 过程中, 分别会涉及 2 个流量端点,即请求的发起端和接收端:

在这个过程中, Envoy 会根据用户规则,计算出符合条件的转发目的主机集合,这个集合叫做 UPSTREAM_CLUSTER, 并根据负载均衡规则,从这个集合中选择一个 host 作为流量转发的接收端点,这个 host 就是 UPSTREAM_HOST。
以上就是 Envoy 请求处理的 流量五元组信息, 这是 Envoy 日志里最重要的部分,通过这个五元组我们可以准确的观测流量「从哪里来」和「到哪里去」。
- UPSTREAM_CLUSTER
- DOWNSTREAM_REMOTE_ADDRESS
- DOWNSTREAM_LOCAL_ADDRESS
- UPSTREAM_LOCAL_ADDRESS
- UPSTREAM_HOST
3. Helloworld example
在 Istio 场景中,Envoy 既可以是正向代理,也可以是反向代理。在上图中, 如果 Envoy 处理的是 Outbound 流量, 业务容器是作为 Downstream 端点(右边);如果 Envoy 处理的是 Inbound 流量, 业务容器是作为 Upstream 端点(左边)。
Istio 中默认不开启 Envoy 中的访问日志,需要手动打开,将 Istio 配置中 accessLogFile 设置为 /dev/stdout:
% kubectl -n istio-system edit cm istio
......
# Set accessLogFile to empty string to disable access log.
accessLogFile: "/dev/stdout" # 开启日志
accessLogEncoding: 'JSON' # 默认日志是单行格式, 可选设置为 JSON
......
我们以 sleep Pod 访问 hello 服务来举例说明:
kubectl apply -f sleep-hello.yaml

该文件定义了 2 个版本的 helloworld 和一个 sleep Pod,helloworld Service 的端口是 4000, 而 Pod 的端口是 5000。
从 sleep Pod 中去访问 helloworld 服务, 确认应用正常:
% SLEEP_POD=$(kubectl get pod -l app=sleep -o jsonpath="{.items[0].metadata.name}")
% HELLO_V1_POD=$(kubectl get pod -l app=helloworld -l version=v1 -o jsonpath="{.items[0].metadata.name}")
% kubectl exec -it $SLEEP_POD -csleep -- sh
/ # curl helloworld:4000/hello
这时候我们可以去分析 2 个 Pod 各自的 Envoy 日志:
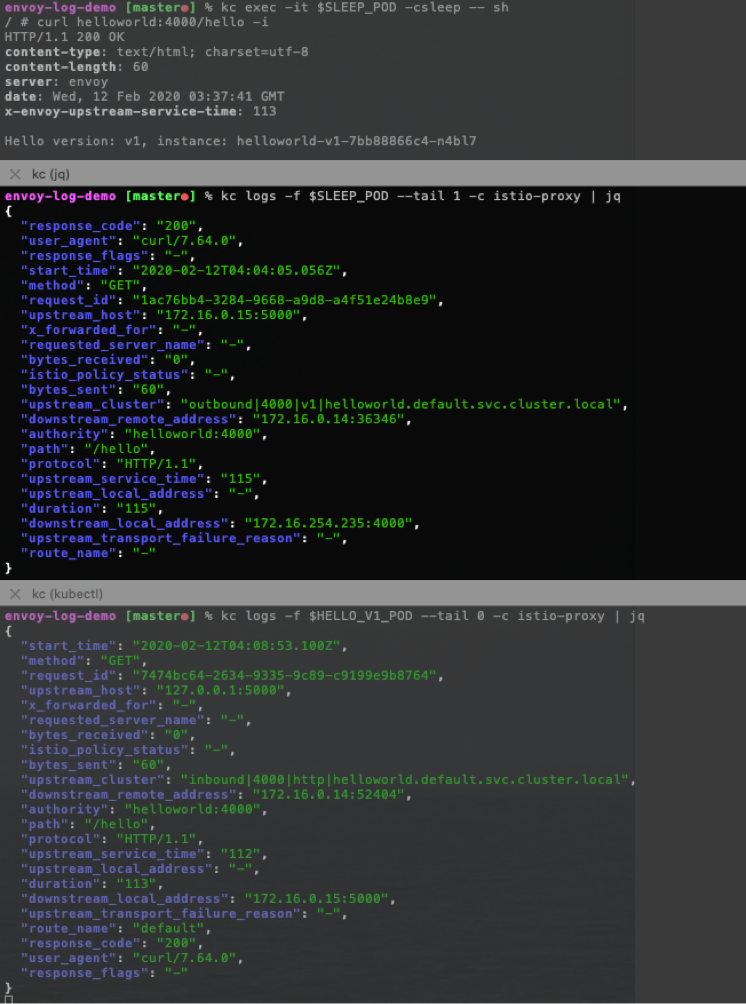
用一张图来说明:

从日志中我们可以分析出:
对于 sleep Pod, sleep app 发出的流量目的端是 hello Service ip 和 Service port,sleep Envoy 处理的是 Outbound 流量, Envoy 根据规则选择的 「UPSTREAM_CLUSTER」是 outbound|4000||helloworld.default.svc.cluster.local , 然后转发给其中的一个 「UPSTREAM_HOST」, 也就是 hello Pod 的 ip 和 port。
对于 hello Pod,其 Envoy 处理的是 Inbound 流量,Envoy 根据规则选择的 「UPSTREAM_CLUSTER」 是 inbound|4000|http|helloworld.default.svc.cluster.local , 其中的 「UPSTREAM_HOST」 是 「127.0.0.1:5000」, 也就是该 Pod 里的 hello app。
因此,我们可以总结出 Istio 中流量端点值的逻辑规则:
UPSTREAM_HOST
上游主机的 host,表示从 Envoy 发出的请求的目的端,通常是「ip:port」
通常来说,对于 Outbound Cluster,此值是「上游 pod-ip : pod-port」 ,而对于 Inbound Cluster,此值是「127.0.0.1 : pod-port」
UPSTREAM_LOCAL_ADDRESS
上游连接中,当前 Envoy 的本地地址,此值是「当前 pod-ip : 随机端口」
DOWNSTREAM_LOCAL_ADDRESS
下游连接中,当前 Envoy 的本地地址。
通常来说,对于 Outbound Cluster,此值是「目的 service-ip : service-port 」,而对于 Inbound Cluster,此值是「当前 pod-ip : pod-port」
DOWNSTREAM_REMOTE_ADDRESS
下游连接中远端地址。
通常来说,对于 Outbound Cluster,此值是「当前 pod-ip : 随机端口 」,而对于 Inbound Cluster,此值是「下游 pod-ip : 随机端口」
4. Envoy 日志格式
Envoy 允许定制日志格式, 格式通过若干「Command Operators」组合,用于提取请求信息,Istio 没有使用 Envoy 默认的日志格式, Istio 定制的访问日志格式如下:
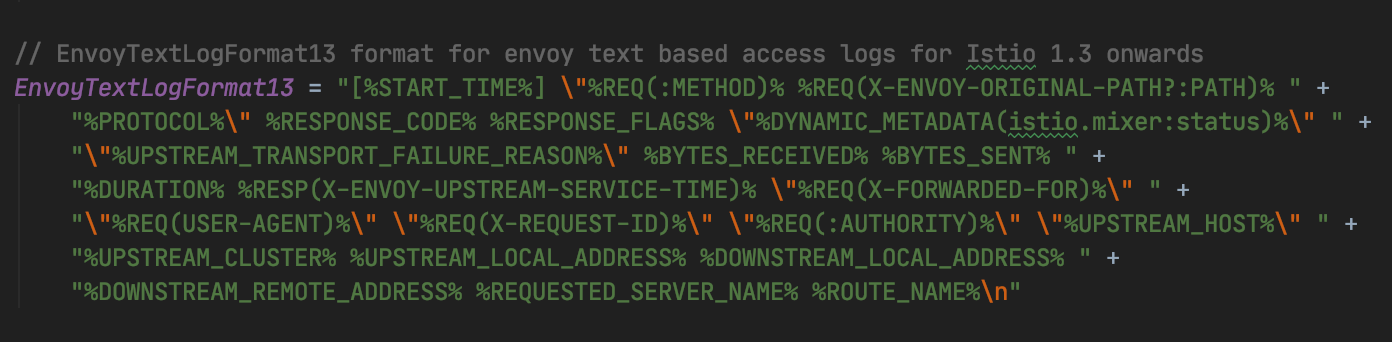
完整的「Command Operators」含义可查阅 Envoy Access logging Command Operators
除了以上流量五元组,流量分析中常用的重要信息还有:
RESPONSE_CODE
响应状态码
RESPONSE_FLAGS
很重要的信息,Envoy 中自定义的响应标志位, 可以认为是 Envoy 附加的流量状态码。
如「NR」表示找不到路由,「UH」表示 Upstream Cluster 中没有健康的 host,「RL」表示触发 rate limit,「UO」触发断路器。
RESPONSE_FLAGS 可选值有十几个,这些信息在调试中非常关键。
X-REQUEST-ID
一次 C 到 S 的 http 请求,Envoy 会在 C 端生产 request id,并附加到 header 中,传递到 S 端,在 2 端的日志中都会记录该值, 因此可以通过这个 ID 关联请求的上下游。注意不要和全链路跟踪中的 trace id 混淆。
ROUTE_NAME
匹配执行的路由名称
5. 场景:判断异常返回是来自业务还是 Sidecar?
比如我们希望所有请求 helloworld 都路由到 v1 版本,创建对应的 VirtualService:
% kubectl apply -f hello-v1-virtualservice.yaml
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: hello
spec:
hosts:
- "helloworld"
http:
- route:
- destination:
host: helloworld
subset: v1
port:
number: 4000
从 sleep 中访问发现响应 503:

如果没有上下文,我们很难判断 503 是来自业务容器还是 Sidecar,查看 sleep 和 hello 的 Envoy 日志,可以发现:hello Pod 的 Envoy 没有接受到请求,sleep Pod 的 Envoy 里日志:
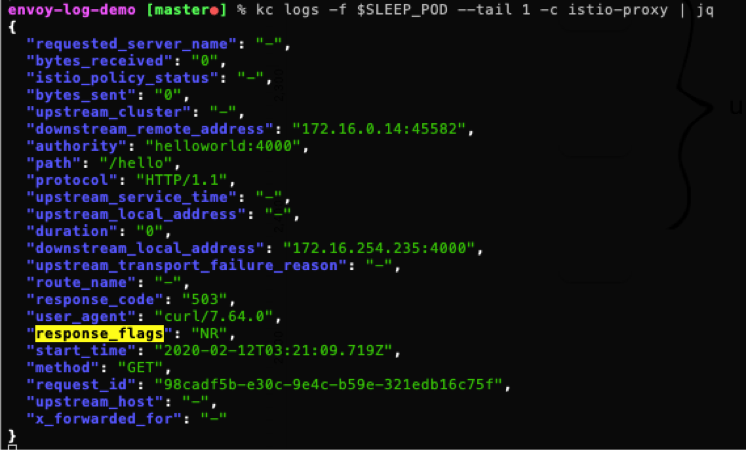
其中 "response_flags": "NR" 表示「No route configured」,也就是 Envoy 找不到路由,我们可以判断出该异常是有 Envoy 返回。
通过简单的分析就可以找到原因, 我们在 VirtualService 中使用的 Destination 没有定义,将其补上:
% kubectl apply -f hello-v1-destinationrule.yaml
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: hello
spec:
host: helloworld
subsets:
- name: v1
labels:
version: v1
再次访问请求正常,日志中 response_flags 为空:
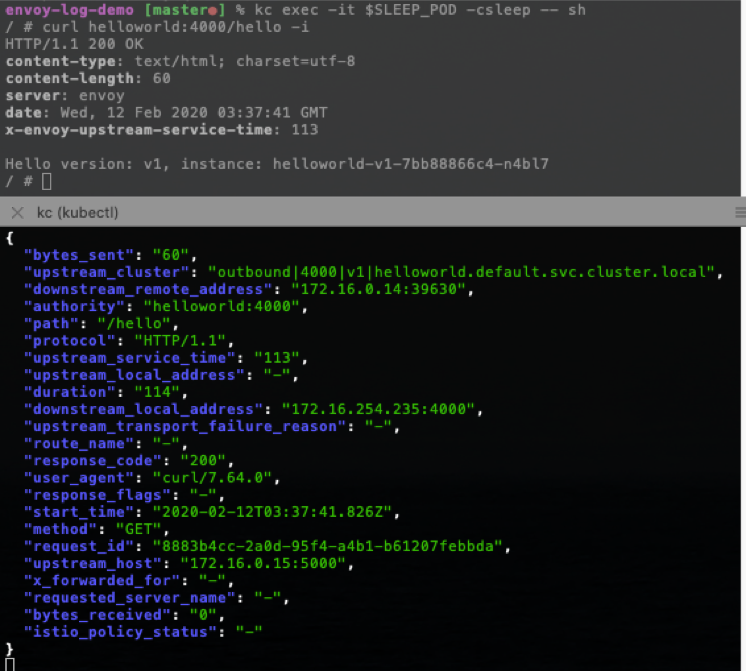
6. 开启 debug 模式
Envoy 默认日志级别是 info,其日志内容能满足大部分调试场景需求,但对于比较复杂的异常,我们往往还需要开启 debug 级别,能获取到更多的流量处理过程和信息,对某个特定的 Pod,调整日志级别为 debug 的命令:
kubectl exec {POD-NAME} -c istio-proxy -- curl -X POST http://127.0.0.1:15000/logging?level=debug
2 - Istio 常见问题
介绍在使用 Istio 过程中可能遇到的一些常见问题的解决方法
2.1 - 应用程序启动失败/启动时无法访问网络
故障现象
该问题的表现是安装了 Sidecar proxy 的应用在启动后的一小段时间内无法通过网络访问 Pod 外面的服务。应用在启动时通常会从一些外部服务中获取数据,并采用这些数据对自身进行初始化。例如从配置中心读取程序配置,从数据库中初始化程序用户信息等。而安装了 Sidecar proxy 的应用在启动后的一小段时间内网络是不通的。如果应用代码中没有合适的容错和重试逻辑,该问题常常会导致应用启动失败。
故障原因
如下图所示,Envoy 启动后会通过 xDS 协议向 Pilot 请求服务和路由配置信息,Pilot 收到请求后会根据 Envoy 所在的节点(Pod 或者 VM)组装配置信息,包括 Listener、Route、Cluster 等,然后再通过 xDS 协议下发给 Envoy。根据 Mesh 的规模和网络情况,该配置下发过程需要数秒到数十秒的时间。在这段时间内,由于初始化容器已经在 Pod 中创建了 Iptables rule 规则,因此应用向外发送的网络流量会被重定向到 Envoy ,而此时 Envoy 中尚没有对这些网络请求进行处理的监听器和路由规则,无法对此进行处理,导致网络请求失败。(关于 Envoy Sidecar 初始化过程和 Istio 流量管理原理的更多内容,可以参考这篇文章 Istio流量管理实现机制深度解析)。

解决方案
参见:最佳实践-在 Sidecar 初始化完成后再启动应用容器
2.2 - ExternalName Service 劫持了其他服务流量
故障现象
如果网格内存在一个 ExternalName 类型 Service, 网格内访问其他外部服务的的某一端口,如果这个端口刚好和该 ExternalName Service 重叠,那么流量会被路由到这个 ExternalName Service 对应的 CDS。
故障重现
正常情况
在 namespace sample 安装 sleep Pod:
kubectl create ns sample
kubectl label ns sample istio-injection=enabled
kubectl -nsample apply -f https://raw.githubusercontent.com/istio/istio/1.11.4/samples/sleep/sleep.yaml
通过 sleep 访问外部服务 https://httpbin.org:443, 请求成功:
kubectl -nsample exec sleep-74b7c4c84c-22zkq -- curl -I https://httpbin.org
HTTP/2 200
......
从 access log 确认流量是从 PassthroughCluster 出去,符合预期:
"- - -" 0 - - - "-" 938 5606 1169 - "-" "-" "-" "-" "18.232.227.86:443" PassthroughCluster 172.24.0.10:42434 18.232.227.86:443 172.24.0.10:42432 - -
异常情况
现在 在 default 下创建一个 ExternalName 类型的 Service, 端口也是 443:
kind: Service
apiVersion: v1
metadata:
name: my-externalname
spec:
type: ExternalName
externalName: bing.com
ports:
- port: 443
targetPort: 443
通过 sleep 访问外部服务 https://httpbin.org:443, 请求失败:
kubectl -nsample exec sleep-74b7c4c84c-22zkq -- curl -I https://httpbin.org
curl: (60) SSL: no alternative certificate subject name matches target host name 'httpbin.org'
More details here: https://curl.se/docs/sslcerts.html
......
查看 access log, 发现请求外部服务,被错误路由到了 my-externalname 的 ExternalName Service:
"- - -" 0 - - - "-" 706 5398 67 - "-" "-" "-" "-" "204.79.197.200:443" outbound|443||my-externalname.default.svc.cluster.local 172.24.0.10:56806 34.192.79.103:443 172.24.0.10:36214 httpbin.org -
故障原因
通过对比 sleep Pod 前后两次的 xDS, 发现增加了 ExternalName Service 后,xDS 里会多一个 LDS 0.0.0.0_443, 该 LDS 包括一个default_filter_chain 会把该 LDS 中其他 filter chain 没有 match 到的流量,都路由到这个 default_filter_chain 中的 Cluster,也就是 my-externalname 对应的 CDS:

解决方案
该问题属于 Istio 实现缺陷,相关 issue: https://github.com/istio/istio/issues/20703
目前的解决方案是避免 ExternalName Service 和其他服务端口冲突。
2.3 - Gateway TLS hosts 冲突导致配置被拒绝
故障现象
网格中同时存在以下两个 Gateway
apiVersion: networking.istio.io/v1beta1
kind: Gateway
metadata:
name: test1
spec:
selector:
istio: ingressgateway
servers:
- hosts:
- test1.example.com
port:
name: https
number: 443
protocol: HTTPS
tls:
credentialName: example-credential
mode: SIMPLE
---
apiVersion: networking.istio.io/v1beta1
kind: Gateway
metadata:
name: test2
spec:
selector:
istio: ingressgateway
servers:
- hosts:
- test1.example.com
- test2.example.com
port:
name: https
number: 443
protocol: HTTPS
tls:
credentialName: example-credential
mode: SIMPLE
172.18.0.6 为 ingress gateway Pod IP,请求 https://test1.example.com 正常返回 404
curl -i -HHost:test1.example.com --resolve "test1.example.com:443:172.18.0.6" --cacert example.com.crt "https://test1.example.com"
HTTP/2 404
date: Mon, 29 Nov 2021 06:59:26 GMT
server: istio-envoy
请求 https://test2.example.com 异常
$ curl -HHost:test2.example.com --resolve "test2.example.com:443:172.18.0.6" --cacert example.com.crt "https://test2.example.com"
curl: (35) OpenSSL SSL_connect: Connection reset by peer in connection to test2.example.com:443
故障原因
通过 istiod 监控发现pilot_total_rejected_configs指标异常,显示default/test2配置被拒绝
 调整 istiod 日志级别查看被拒绝的原因
调整 istiod 日志级别查看被拒绝的原因
--log_output_level=model:debug
2021-11-29T07:24:21.703924Z debug model skipping server on gateway default/test2, duplicate host names: [test1.example.com]
通过日志定位到具体代码位置
if duplicateHosts := CheckDuplicates(s.Hosts, tlsHostsByPort[resolvedPort]); len(duplicateHosts) != 0 {
log.Debugf("skipping server on gateway %s, duplicate host names: %v", gatewayName, duplicateHosts)
RecordRejectedConfig(gatewayName)
continue
}
// CheckDuplicates returns all of the hosts provided that are already known
// If there were no duplicates, all hosts are added to the known hosts.
func CheckDuplicates(hosts []string, knownHosts sets.Set) []string {
var duplicates []string
for _, h := range hosts {
if knownHosts.Contains(h) {
duplicates = append(duplicates, h)
}
}
// No duplicates found, so we can mark all of these hosts as known
if len(duplicates) == 0 {
for _, h := range hosts {
knownHosts.Insert(h)
}
}
return duplicates
}
校验逻辑是每个域名在同一端口上只能配置一次 TLS,我们这里 test1.example.com 在 2 个 Gateway 的 443 端口都配置了 TLS,
导致其中一个被拒绝,通过监控确认被拒绝的是 test2,test2.example.com 和 test1.example.com 配置在 test2 的同一个 Server,Server 配置被拒绝导致请求异常
解决方案
同一个域名不要在多个 Gateway 中的同一端口重复配置 TLS,这里我们删除 test1 后请求恢复正常
$ curl -i -HHost:test1.example.com --resolve "test1.example.com:443:172.18.0.6" --cacert example.com.crt "https://test1.example.com"
HTTP/2 404
date: Mon, 29 Nov 2021 07:43:40 GMT
server: istio-envoy
$ curl -i -HHost:test2.example.com --resolve "test2.example.com:443:172.18.0.6" --cacert example.com.crt "https://test2.example.com"
HTTP/2 404
date: Mon, 29 Nov 2021 07:43:41 GMT
server: istio-envoy
2.4 - Server Speaks First 协议访问失败
故障现象
Istio 网格开启 allow any 访问模式,在一个注入了 sidecar 的 pod 内,mysql 客户端访问 mysql-ip-1:3306 成功,访问 mysql-ip-2:10000 没有响应:
# mysql -h55.135.153.1 -utest -pxxxx -P3306
Welcome to the MariaDB monitor. Commands end with ; or \g.
# mysql -h55.108.108.2 -utest -pxxxx -P10000
(no response)
故障分析
查看日志,把 access log 设置为 debug、trace 均没有发现有用信息。
分析发现,网格内有一个 http server,也使用了和 mysql-ip-2 相同的端口 10000:
apiVersion: v1
kind: Service
metadata:
name: irrelevant-svc
......
spec:
ports:
- name: http
nodePort: 31025
port: 10000 # 端口相同
protocol: TCP
targetPort: 8080
我们尝试把该服务端口改成 10001,访问 mysql-ip-2:10000 成功,推测和端口冲突相关:
# mysql -h55.108.108.2 -utest -pxxxx -P10000
Welcome to the MariaDB monitor. Commands end with ; or \g.
我们再尝试对 mysql-ip-1 复现故障:在网格内创建了一个包括 3306 端口的 http 服务,mysql 请求无响应,问题复现。
另外我们还尝试过,如果把冲突端口的协议定义为 tcp(通过 port name),该问题不存在:
apiVersion: v1
kind: Service
metadata:
name: irrelevant-svc
......
spec:
ports:
- name: tcp # 如果是 tcp 则不会出问题
nodePort: 31025
port: 10000
protocol: TCP
targetPort: 8080
故障原因
Server Speaks First
Mysql 协议是一种 Server Speaks First 协议,也就是说 client 和 server 完成三次握手后,是 server 会先发起会话, 简要过程:
S: 服务端首先会发一个握手包到客户端
C: 客户端向服务端发送认证信息 ( 用户名,密码等 )
S: 服务端收到认证包后,会检查用户名与密码是否合法,并发送包告知客户端认证信息。
除了 Mysql,常见的 Server Speaks First 协议还包括 SMTP,DNS,MongoDB 等。下面是一个 SMTP 交互流程:
S: 220 smtp.example.com ESMTP Postfi
C: HELO relay.example.com
S: 250 smtp.example.com, I am glad to meet you
C: MAIL FROM:<bob@example.com>
S: 250 Ok
C: RCPT TO:<alice@example.com>
S: 250 Ok
C: RCPT TO:<theboss@example.com>
S: 250 Ok
C: DATA
S: 354 End data with <CR><LF>.<CR><LF>
C: From: "Bob Example" <bob@example.com>
C: To: Alice Example <alice@example.com>
C: Cc: theboss@example.com
C: Date: Tue, 15 Jan 2008 16:02:43 -0500
C: Subject: Test message
C:
C: Hello Alice.
C: This is a test message with 5 header fields and 4 lines in the message body.
C: Your friend,
C: Bob
C: .
S: 250 Ok: queued as 12345
C: QUIT
S: 221 Bye
{The server closes the connection}
istio 不是完全透明
当前 istio 的某些特性,不能做到透明兼容 Server Speaks First 协议,这些特性包括:
- 协议嗅探
- PERMISSIVE mTLS
- Authorization Policy
这些特性都希望 client 能先发起会话,以协议嗅探为例,envoy 是通过分析 client 发出的初始若干字节来推测协议类型。
对于 Server Speaks First 协议,比如 mysql,三次握手后,这时候 mysql client 在等待 mysql server 发起初次会话,而 client 端的 envoy 尝试做协议嗅探,也在等 mysql client 发出数据,这类似一个死锁,最终超时。
解决方案
以下是一些可行的方案:
- 为 Server Speaks First 协议服务创建一个 ServiceEntry,并指定协议为 TCP。
- 避免 Server Speaks First 协议服务端口和网格内服务端口重叠,这样请求可以直接走 passthrough。
- 把 Server Speaks First 服务 ip 放到 excludeIPRanges,这样请求不经过 envoy 处理,适用于 DB 服务不需要网格治理的情况。
参考资料
2.5 - 长连接未开启 tcp keepalive
故障现象
用户反馈链路偶发 500 错误,频率低但是持续存在。
用户访问链路较长,核心链路简化如下:
1. client ->
2. [istio ingress gateway] ->
3. podA[app->sidecar] ->
4. 腾讯云内网CLB ->
5. [istio ingress gateway] ->
6. podB[sidecar->app]
应用对外是 https 服务,证书在 istio ingress gateway 上处理。
故障分析
通过分析链路中 sidecar accesslog 日志,有以下现象:
- 第 3 跳 podA 正常发出请求,但接收到 500 返回。
- 第 5 跳 istio ingress gateway 没有该 500 对应的访问日志。
因此重点分析 第 3,4,5 跳。
在第 3 跳 podA 上抓到 500 对应的数据包:

抓包显示,podA 向一个已经断开的连接发送数据包,收到 RST 因此返回 500,但抓包并没有发现这个连接之前有主动断开的行为(FIN)。
登录 podA,查看连接情况:

ss 显示用户代码里使用了 tcp 长连接,注意这里我们使用了 ss 参数 -o, 该参数可以显示 tcp keepalive timer 信息:
-o, --options
Show timer information. For TCP protocol, the output
format is:
timer:(<timer_name>,<expire_time>,<retrans>)
<timer_name>
the name of the timer, there are five kind of timer
names:
on : means one of these timers: TCP retrans timer,
TCP early retrans timer and tail loss probe timer
keepalive: tcp keep alive timer
timewait: timewait stage timer
persist: zero window probe timer
unknown: none of the above timers
<expire_time>
how long time the timer will expire
<retrans>
how many times the retransmission occurred
但从 ss 结果并未看到 timer 信息,推断 podA 使用的长连接并未开启 keepalive。
故障原因
podA 使用了 tcp 长连接,但是没有开启 keepalive,当长连接出现一段时间空闲,该连接可能被网络中间组件释放,比如 client、server 端的母机, 但 client 端还是持有断开连接,后续重用该链接就会导致上述异常。
解决方案
问题本质是因为长连接 idle 过长,且缺乏探活机制,导致 client 没感知到连接已释放,尝试三种方案:
- 应用代码修复
- istio 方案:client sidecar 开启 keepalive
- istio 方案:server 开启 keepalive
应用代码修复
最直接的方案是应用在使用长连接时,开启 tcp keepalive,以 golang 程序示例,我们尝试用长连接访问 https://www.baidu.com
先模拟使用长连接但不开启 keepalive:
var HTTPTransport = &http.Transport{
DialContext: (&net.Dialer{
Timeout: 10 * time.Second,
KeepAlive: -1 * time.Second, // disable TCP KeepAlive
}).DialContext,
MaxIdleConns: 50,
IdleConnTimeout: 60 * time.Second,
MaxIdleConnsPerHost: 20,
}
func main() {
uri := "https://www.baidu.com"
times := 200
client := http.Client{Transport: HTTPTransport}
for i := 0; i < times; i++ {
time.Sleep(2 * time.Second)
req, err := http.NewRequest(http.MethodGet, uri, nil)
if err != nil {
fmt.Println("NewRequest Failed " + err.Error())
continue
}
resp, err := client.Do(req)
if err != nil {
fmt.Println("Http Request Failed " + err.Error())
continue
}
fmt.Println(resp.Status)
ioutil.ReadAll(resp.Body)
resp.Body.Close()
}
注意 KeepAlive: -1 表示禁用了 tcp keepalive 探活,ss 查看:

结果显示长连接缺乏 timer。注意测试 pod 在 istio 环境,上述第一个连接是 go 程序到 envoy,第二个连接是 envoy 到 baidu。
golang 代码修复方案很简单,只需要把 KeepAlive 设置为非负数, 代码修改
var HTTPTransport = &http.Transport{
DialContext: (&net.Dialer{
Timeout: 10 * time.Second,
KeepAlive: 120 * time.Second, // keepalive 设置为 2 分钟
}).DialContext,
MaxIdleConns: 50,
IdleConnTimeout: 60 * time.Second,
MaxIdleConnsPerHost: 20,
}
ss 查看连接情况:

ss 显示 go client 到 envoy 开启了 keepalive,问题解决。
但用户应用程序较多,不方便逐一调整 keepalive,希望通过 istio sidecar 来解决上述问题。keepalive 可以在 client、server 任意一端开启,以下是使用 istio 的两种方案:
istio 方案:client sidecar 开启 keepalive
该方案需要client 注入 istio sidecar,仍以访问 baidu https 为例,外部服务在 istio 中默认转发到 PassthroughCluster, 要对指定外部服务流量进行流控,我们需要先给该服务创建一个 service entry:
apiVersion: networking.istio.io/v1alpha3
kind: ServiceEntry
metadata:
name: baidu-https
spec:
hosts:
- www.baidu.com
location: MESH_EXTERNAL
ports:
- number: 443
name: https
protocol: TLS
然后增加 tcp keepalive 设置:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: baidu-https
spec:
host: www.baidu.com
trafficPolicy:
connectionPool:
tcp:
maxConnections: 100
tcpKeepalive:
time: 600s
interval: 75s
probes: 9

ss 显示 go client 到 envoy 并没有 keepalive, 但 envoy 到 baidu 开启了 keepalive。
istio 方案:server 开启 keepalive
用户异常链路的 server 入口 是 CLB 后端的 ingress gateway,在 ingress gateway 上开启 keepalive 会稍微复杂一点,需要使用 envoyfilter 来设置 socekt options:
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: ingress-gateway-socket-options
namespace: istio-system
spec:
configPatches:
- applyTo: LISTENER
match:
context: GATEWAY
listener:
name: 0.0.0.0_443
portNumber: 443
patch:
operation: MERGE
value:
socket_options:
- int_value: 1
level: 1 # SOL_SOCKET
name: 9 # SO_KEEPALIVE
state: STATE_PREBIND
- int_value: 9
level: 6 # IPPROTO_TCP
name: 6 # TCP_KEEPCNT
state: STATE_PREBIND
- int_value: 600
level: 6 # IPPROTO_TCP
name: 4 # TCP_KEEPIDLE
state: STATE_PREBIND
- int_value: 75
level: 6 # IPPROTO_TCP
name: 5 # TCP_KEEPINTVL
state: STATE_PREBIND
上述配置的含义是:对于 433 LDS,tcp 连接设置 socket options:连接空闲 600s 后,开始发送探活 probe;如果探活失败,会持续探测 9 次,探测间隔为 75 s。
在 ingress gateway 上 ss, 显示 443 上连接都开启了 keepalive:

如果用户 client 较多不便调整,更适合在 server (ingress gateway)开启 keepalive。另外该方案对 client 有无 sidecar 没有要求。
总结
使用长连接时,应用需要设置合理的 keepalive 参数,特别是对于访问频次较低的场景,以及链路较长的情况。
istio 无入侵式的流量操纵能力,可以很方便的对流量行为进行调优,这也是用户选择 istio 的重要原因。
参考资料
3 - Istio 最佳实践
介绍用户从 Spring Cloud,Dubbo 等传统微服务框架迁移到 Istio 服务网格时的最佳实践
3.1 - Sidecar 初始化完成后再启动应用程序
为什么需要配置 Sidecar 和应用程序的启动顺序?
在安装了 Sidecar Proxy 的 Pod 中,应用发出的外部网络请求会被 Iptables 规则重定向到 Proxy 中。如果应用发出请求时 Proxy 还未初始化完成,则 Proxy 无法对请求进行正确路由,导致请求失败。该问题导致的故障现象参见 常见问题-应用程序启动失败/启动时无法访问网络。
配置方法 - Istio 1.7 及之后版本
Istio 1.7 及之后的版本中,可以通过下面的方法配置在 Sidecar 初始化完成后再启动应用容器。
全局配置:
在 istio-system/istio ConfigMap 中将 holdApplicationUntilProxyStarts 这个全局配置项设置为 true。
apiVersion: v1
data:
mesh: |-
defaultConfig:
holdApplicationUntilProxyStarts: true
按 Deployment 配置:
如果不希望该配置全局生效,则可以通过下面的 annotation 在 Deployment 级别进行配置。
template:
metadata:
annotations:
proxy.istio.io/config: '{ "holdApplicationUntilProxyStarts": true }'
实现原理:在开启 holdApplicationUntilProxyStarts 选项后,Istio Sidecar Injector Webhook 会在 Pod 中插入下面的 yaml 片段。该 yaml 片段在 Sidecar proxy 的 postStart 生命周期时间中执行了 pilot-agent wait 命令。该命令会检测 Proxy 的状态,待 Proxy 初始化完成后再启动 Pod 中的下一个容器。这样,在应用容器启动时,Sidecar proxy 已经完成了配置初始化,可以正确代理应用容器的对外网络请求。
spec:
containers:
- name: istio-proxy
lifecycle:
postStart:
exec:
command:
- pilot-agent
- wait
配置方法 - Istio 1.7 之前的版本
Istio 1.7 之前的版本没有直接提供配置 Sidecar 和应用容器启动顺序的能力。由于 Istio 新版本中解决了老版本中的很多故障,建议尽量升级到新版本。如果由于特殊原因还要继续使用 Istio 1.7 之前的版本,可以在应用进程启动时判断 Envoy Sidecar 的初始化状态,待其初始化完成后再启动应用进程。
Envoy 的健康检查接口 localhost:15020/healthz/ready 会在 xDS 配置初始化完成后才返回 200,否则将返回 503,因此可以根据该接口判断 Envoy 的配置初始化状态,待其完成后再启动应用容器。我们可以在应用容器的启动命令中加入调用 Envoy 健康检查的脚本,如下面的配置片段所示。在其他应用中使用时,将 start-awesome-app-cmd 改为容器中的应用启动命令即可。
apiVersion: apps/v1
kind: Deployment
metadata:
name: awesome-app-deployment
spec:
selector:
matchLabels:
app: awesome-app
replicas: 1
template:
metadata:
labels:
app: awesome-app
spec:
containers:
- name: awesome-app
image: awesome-app
ports:
- containerPort: 80
command: ["/bin/bash", "-c"]
args: ["while [[ \"$(curl -s -o /dev/null -w ''%{http_code}'' localhost:15020/healthz/ready)\" != '200' ]]; do echo Waiting for Sidecar;sleep 1; done; echo Sidecar available; start-awesome-app-cmd"]
解耦应用服务之间的启动依赖关系
以上配置的思路是控制 Pod 中容器的启动顺序,在 Envoy Sidecar 初始化完成后再启动应用容器,以确保应用容器启动时能够通过网络正常访问其他服务。但即使 Pod 中对外的网络访问没有问题,应用容器依赖的其他服务也可能由于尚未启动,或者某些问题而不能在此时正常提供服务。要彻底解决该问题,建议解耦应用服务之间的启动依赖关系,使应用容器的启动不再强依赖其他服务。
在一个微服务系统中,原单体应用中的各个业务模块被拆分为多个独立进程(服务)。这些服务的启动顺序是随机的,并且服务之间通过不可靠的网络进行通信。微服务多进程部署、跨进程网络通信的特定决定了服务之间的调用出现异常是一个常见的情况。为了应对微服务的该特点,微服务的一个基本的设计原则是 “design for failure”,即需要以优雅的方式应对可能出现的各种异常情况。当在微服务进程中不能访问一个依赖的外部服务时,需要通过重试、降级、超时、断路等策略对异常进行容错处理,以尽可能保证系统的正常运行。
Envoy Sidecar 初始化期间网络暂时不能访问的情况只是放大了微服务系统未能正确处理服务依赖的问题,即使解决了 Envoy Sidecar 的依赖顺序,该问题依然存在。假设应用启动时依赖配置中心,配置中心是一个独立的微服务,当一个依赖配置中心的微服务启动时,配置中心有可能尚未启动,或者尚未初始化完成。在这种情况下,如果在代码中没有对该异常情况进行处理,也会导致依赖配置中心的微服务启动失败。在一个更为复杂的系统中,多个微服务进程之间可能存在网状依赖关系,如果没有按照 “design for failure” 的原则对微服务进行容错处理,那么只是将整个系统启动起来就将是一个巨大的挑战。
3.2 - 在 Istio 中指定 HTTP Header 大小写
问题背景
Envoy 缺省会把 HTTP Header 的 key 转换为小写,例如有一个 HTTP Header Test-Upper-Case-Header: some-value,经过 Envoy 代理后会变成 test-upper-case-header: some-value。这个在正常情况下没问题,RFC 2616 规范也说明了处理 HTTP Header 应该是大小写不敏感的。
部分场景下,业务请求对某些 Header 字段有大小写要求,此时被 Envoy 转换成为小些会导致请求出现问题。
解决方案
Envoy 支持几种不同的 Header 规则:
Envoy 1.8 之后新增支持:
基于以上能力,为了解决 Header 默认改为小写的问题在 Istio 1.8 及之前可配置成为首字母大写形式,Istio 1.10 及以后可以配置保留 Header 原有样式。
配置方法
Istio 1.8 之前可添加如下 EnvoyFilter 配置:
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: http-header-proper-case-words
namespace: istio-system
spec:
configPatches:
- applyTo: CLUSTER
match:
context: SIDECAR_OUTBOUND
cluster:
# 集群名称可通过 ConfigDump 查询
name: "outbound|3000||test2.default.svc.cluster.local"
patch:
operation: MERGE
value:
http_protocol_options:
header_key_format:
proper_case_words: {}
在需要依赖大写 Header 的服务对应的集群中添加规则,将 Header 全部转为首字母大写的形式。
Istio 1.10 及之后可以添加如下 EnvoyFilter 配置:
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: http-header-proper-case-words
namespace: istio-system
spec:
configPatches:
# 配置保留发向 upstream 的 request header 大小写
- applyTo: CLUSTER
patch:
operation: MERGE
value:
typed_extension_protocol_options:
envoy.extensions.upstreams.http.v3.HttpProtocolOptions:
'@type': type.googleapis.com/envoy.extensions.upstreams.http.v3.HttpProtocolOptions
use_downstream_protocol_config:
http_protocol_options:
header_key_format:
stateful_formatter:
name: preserve_case
typed_config:
'@type': type.googleapis.com/envoy.extensions.http.header_formatters.preserve_case.v3.PreserveCaseFormatterConfig
# 配置保留收到的 response header 大小写
- applyTo: NETWORK_FILTER
match:
listener:
filterChain:
filter:
name: envoy.filters.network.http_connection_manager
patch:
operation: MERGE
value:
typed_config:
'@type': type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
http_protocol_options:
header_key_format:
stateful_formatter:
name: preserve_case
typed_config:
'@type': type.googleapis.com/envoy.extensions.http.header_formatters.preserve_case.v3.PreserveCaseFormatterConfig
通过此配置可以让 Envoy 保持 Header 原有大小写形式。
Envoy 文档中对此的说明: https://www.envoyproxy.io/docs/envoy/latest/configuration/http/http_conn_man/header_casing#config-http-conn-man-header-casing
3.3 - Sidecar 初始化完成后再启动应用程序
Envoy 内部重定向
Envoy 支持在内部处理 3xx 重定向,捕获可配置的 3xx 重定向响应,合成一个新的请求,将其发送给新路由匹配指定的上游,将重定向的响应作为对原始请求的响应返回。原始请求的 header 和 body 将会发送至新位置。Trailers 尚不支持。
内部重定向可以使用路由配置中的 internal_redirect_policy 字段来配置。 当重定向处理开启,任何来自上游的 3xx 响应,只要匹配到配置的 redirect_response_codes 的响应都将由 Envoy 来处理。
如果 Envoy 内部重定向配置了 303 并且接收到了 303 响应,如果原始请求不是 GET 或者 HEAD,Envoy 将使用没有 body 的 GET 处理重定向。如果原始请求是 GET 或者 HEAD,Envoy 将使用原始的 HTTP Method 处理重定向。更多信息请查看 RFC 7231 Section 6.4.4 。
要成功地处理重定向,必须通过以下检查:
- 响应码匹配到配置的 redirect_response_codes ,默认是 302, 或者其他的 3xx 状态码(301, 302, 303, 307, 308)。
- 拥有一个有效的、完全限定的 URL 的 location 头。
- 该请求必须已被 Envoy 完全处理。
- 请求必须小于 per_request_buffer_limit_bytes 的限制。
- allow_cross_scheme_redirect 是 true(默认是 false), 或者下游请求的 scheme 和 location 头一致。
- 给定的下游请求之前处理的内部重定向次数不超过请求或重定向请求命中的路由配置的 max_internal_redirects 。
- 所有 predicates 都接受目标路由。
任何失败都将导致重定向传递给下游。
由于重定向请求可能会在不同的路由之间传递,重定向链中的任何满足以下条件的路由都将导致重定向被传递给下游。
- 没有启用内部重定向
- 或者当重定向链命中的路由的 max_internal_redirects 小于等于重定向链的长度。
- 或者路由被 predicates 拒绝。
previous_routes 和 allow_listed_routes 这两个 predicates 可以创建一个有向无环图 (DAG) 来定义一个过滤器链,具体来说,allow_listed_routes 定义的有向无环图(DAG)中各个节点的边,而 previous_routes 定义了边的“访问”状态,因此如果需要就可以避免循环。
第三个 predicate safe_cross_scheme 被用来阻止 HTTP -> HTTPS 的重定向。
一旦重定向通过这些检查,发送到原始上游的请求头将被修改为:
- 将完全限定的原始请求 URL 放到 x-envoy-original-url 头中。
- 使用 Location 头中的值替换 Authority/Host、Scheme、Path 头。
修改后的请求头将选择一个新的路由,通过一个新的过滤器链发送,然后把所有正常的 Envoy 请求都发送到上游进行清理。
请注意,HTTP 连接管理器头清理(例如清除不受信任的标头)仅应用一次。即使原始路由和第二个路由相同,每个路由的头修改也将同时应用于原始路由和第二路由,因此请谨慎配置头修改规则, 以避免重复不必要的请求头值。
一个简单的重定向流如下所示:
- 客户端发送 GET 请求以获取 http://foo.com/bar
- 上游 1 发送 302 响应码并携带 “location: http://baz.com/eep”
- Envoy 被配置为允许原始路由上重定向,并发送新的 GET 请求到上游 2,携带请求头 “x-envoy-original-url: http://foo.com/bar” 获取 http://baz.com/eep
- Envoy 将 http://baz.com/eep 的响应数据代理到客户端,作为对原始请求的响应。
在 Isito 中通过 Envoyfilter 开启内部重定向
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: follow-redirects
namespace: istio-system
spec:
workloadSelector:
labels:
app: istio-ingressgateway
configPatches:
- applyTo: HTTP_ROUTE
match:
context: ANY
patch:
operation: MERGE
value:
route:
internal_redirect_policy:
max_internal_redirects: 5
redirect_response_codes: ["302"]
测试
开启前
curl -i '172.16.0.2/redirect-to?url=http://172.16.0.2/status/200'
HTTP/1.1 302 Found
server: istio-envoy
date: Fri, 11 Mar 2022 07:20:38 GMT
content-type: text/html; charset=utf-8
content-length: 0
location: http://172.16.0.2/status/200
access-control-allow-origin: *
access-control-allow-credentials: true
x-envoy-upstream-service-time: 1
开启后
curl -i '172.16.0.2/redirect-to?url=http://172.16.0.2/status/200'
HTTP/1.1 200 OK
server: istio-envoy
date: Fri, 11 Mar 2022 07:21:03 GMT
content-type: text/html; charset=utf-8
access-control-allow-origin: *
access-control-allow-credentials: true
content-length: 0
x-envoy-upstream-service-time: 0
注意 location 需返回完整 URL,下面这种情况不会触发内部重定向
curl -i '172.16.0.2/status/302'
HTTP/1.1 302 Found
server: istio-envoy
date: Fri, 11 Mar 2022 07:30:38 GMT
location: /redirect/1
access-control-allow-origin: *
access-control-allow-credentials: true
content-length: 0
x-envoy-upstream-service-time: 1
参考资料
3.4 - 在 Istio 中实现方法级调用跟踪
本文将通过一个网上商店的示例程序介绍如何利用 Spring 和 OpenTracing 简化应用程序的 Tracing 上下文传递,以及如何在 Istio 提供的进程间调用跟踪基础上实现方法级别的细粒度调用跟踪。
分布式调用跟踪和 OpenTracing 规范
什么是分布式调用跟踪?
相比传统的“巨石”应用,微服务的一个主要变化是将应用中的不同模块拆分为了独立的进程。在微服务架构下,原来进程内的方法调用成为了跨进程的 RPC 调用。相对于单一进程的方法调用,跨进程调用的调试和故障分析是非常困难的,很难用传统的调试器或者日志打印来对分布式调用进行查看和分析。
 如上图所示,一个来自客户端的请求经过了多个微服务进程。如果要对该请求进行分析,则必须将该请求经过的所有服务的相关信息都收集起来并关联在一起,这就是“分布式调用跟踪”。
如上图所示,一个来自客户端的请求经过了多个微服务进程。如果要对该请求进行分析,则必须将该请求经过的所有服务的相关信息都收集起来并关联在一起,这就是“分布式调用跟踪”。
什么是 OpenTracing?
CNCF OpenTracing 项目
OpenTracing是CNCF(云原生计算基金会)下的一个项目,其中包含了一套分布式调用跟踪的标准规范,各种语言的 API,编程框架和函数库。OpenTracing 的目的是定义一套分布式调用跟踪的标准,以统一各种分布式调用跟踪的实现。目前已有大量支持 OpenTracing 规范的 Tracer 实现,包括 Jager,Skywalking,LightStep 等。在微服务应用中采用 OpenTracing API 实现分布式调用跟踪,可以避免 vendor locking,以最小的代价和任意一个兼容 OpenTracing 的基础设施进行对接。
OpenTracing 概念模型
OpenTracing 的概念模型参见下图:
 图源自 https://opentracing.io/
如图所示,OpenTracing 中主要包含下述几个概念:
图源自 https://opentracing.io/
如图所示,OpenTracing 中主要包含下述几个概念:
- Trace: 描述一个分布式系统中的端到端事务,例如来自客户端的一个请求。
- Span:一个具有名称和时间长度的操作,例如一个 REST 调用或者数据库操作等。Span 是分布式调用跟踪的最小跟踪单位,一个 Trace 由多段 Span 组成。
- Span context:分布式调用跟踪的上下文信息,包括 Trace id,Span id 以及其它需要传递到下游服务的内容。一个 OpenTracing 的实现需要将 Span context 通过某种序列化机制(Wire Protocol)在进程边界上进行传递,以将不同进程中的 Span 关联到同一个 Trace 上。这些 Wire Protocol 可以是基于文本的,例如 HTTP header,也可以是二进制协议。
OpenTracing 数据模型
一个 Trace 可以看成由多个相互关联的 Span 组成的有向无环图(DAG 图)。下图是一个由 8 个 Span 组成的 Trace:
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C is a `ChildOf` Span A)
| |
[Span D] +---+-------+
| |
[Span E] [Span F] >>> [Span G] >>> [Span H]
↑
↑
↑
(Span G `FollowsFrom` Span F)
上图的 trace 也可以按照时间先后顺序表示如下:
––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time
[Span A···················································]
[Span B··············································]
[Span D··········································]
[Span C········································]
[Span E·······] [Span F··] [Span G··] [Span H··]
Span 的数据结构中包含以下内容:
- name: Span 所代表的操作名称,例如 REST 接口对应的资源名称。
- Start timestamp: Span 所代表操作的开始时间
- Finish timestamp: Span 所代表的操作的的结束时间
- Tags:一系列标签,每个标签由一个 key value 键值对组成。该标签可以是任何有利于调用分析的信息,例如方法名,URL 等。
- SpanContext:用于跨进程边界传递 Span 相关信息,在进行传递时需要结合一种序列化协议(Wire Protocol)使用。
- References:该 Span 引用的其它关联 Span,主要有两种引用关系,Childof 和 FollowsFrom。
- Childof: 最常用的一种引用关系,表示 Parent Span 和 Child Span 之间存在直接的依赖关系。例 RPC 服务端 Span 和 RPC 客户端 Span,或者数据库 SQL 插入 Span 和 ORM Save 动作 Span 之间的关系。
- FollowsFrom:如果 Parent Span 并不依赖 Child Span 的执行结果,则可以用 FollowsFrom 表示。例如网上商店购物付款后会向用户发一个邮件通知,但无论邮件通知是否发送成功,都不影响付款成功的状态,这种情况则适用于用 FollowsFrom 表示。
跨进程调用信息传播
SpanContext 是 OpenTracing 中一个让人比较迷惑的概念。在 OpenTracing 的概念模型中提到 SpanContext 用于跨进程边界传递分布式调用的上下文。但实际上 OpenTracing 只定义一个 SpanContext 的抽象接口,该接口封装了分布式调用中一个 Span 的相关上下文内容,包括该 Span 所属的 Trace id,Span id 以及其它需要传递到 downstream 服务的信息。SpanContext 自身并不能实现跨进程的上下文传递,需要由 Tracer(Tracer 是一个遵循 OpenTracing 协议的实现,如 Jaeger,Skywalking 的 Tracer)将 SpanContext 序列化后通过 Wire Protocol 传递到下一个进程中,然后在下一个进程将 SpanContext 反序列化,得到相关的上下文信息,以用于生成 Child Span。
为了为各种具体实现提供最大的灵活性,OpenTracing 只是提出了跨进程传递 SpanContext 的要求,并未规定将 SpanContext 进行序列化并在网络中传递的具体实现方式。各个不同的 Tracer 可以根据自己的情况使用不同的 Wire Protocol 来传递 SpanContext。
在基于 HTTP 协议的分布式调用中,通常会使用 HTTP Header 来传递 SpanContext 的内容。常见的 Wire Protocol 包含 Zipkin 使用的 b3 HTTP header,Jaeger 使用的 uber-trace-id HTTP Header,LightStep 使用的 “x-ot-span-context” HTTP Header 等。Istio/Envoy 支持 b3 header 和 x-ot-span-context header,可以和 Zipkin,Jaeger 及 LightStep 对接。其中 b3 HTTP header 的示例如下:
X-B3-TraceId: 80f198ee56343ba864fe8b2a57d3eff7
X-B3-ParentSpanId: 05e3ac9a4f6e3b90
X-B3-SpanId: e457b5a2e4d86bd1
X-B3-Sampled: 1
Istio 对分布式调用跟踪的支持
Istio/Envoy 为微服务提供了开箱即用的分布式调用跟踪功能。在安装了 Istio 和 Envoy 的微服务系统中,Envoy 会拦截服务的入向和出向请求,为微服务的每个调用请求自动生成调用跟踪数据。通过在服务网格中接入一个分布式跟踪的后端系统,例如 Zipkin 或者 Jaeger,就可以查看一个分布式请求的详细内容,例如该请求经过了哪些服务,调用了哪个 REST 接口,每个 REST 接口所花费的时间等。
需要注意的是,Istio/Envoy 虽然在此过程中完成了大部分工作,但还是要求对应用代码进行少量修改:应用代码中需要将收到的上游 HTTP 请求中的 b3 header 拷贝到其向下游发起的 HTTP 请求的 header 中,以将调用跟踪上下文传递到下游服务。这部分代码不能由 Envoy 代劳,原因是 Envoy 并不清楚其代理的服务中的业务逻辑,无法将入向请求和出向请求按照业务逻辑进行关联。这部分代码量虽然不大,但需要对每一处发起 HTTP 请求的代码都进行修改,非常繁琐而且容易遗漏。当然,可以将发起 HTTP 请求的代码封装为一个代码库来供业务模块使用,来简化该工作。
下面以一个简单的网上商店示例程序来展示 Istio 如何提供分布式调用跟踪。该示例程序由 eshop,inventory,billing,delivery 几个微服务组成,结构如下图所示:
 eshop 微服务接收来自客户端的请求,然后调用 inventory,billing,delivery 这几个后端微服务的 REST 接口来实现用户购买商品的 checkout 业务逻辑。本例的代码可以从 github 下载:https://github.com/aeraki-framework/method-level-tracing-with-istio
eshop 微服务接收来自客户端的请求,然后调用 inventory,billing,delivery 这几个后端微服务的 REST 接口来实现用户购买商品的 checkout 业务逻辑。本例的代码可以从 github 下载:https://github.com/aeraki-framework/method-level-tracing-with-istio
如下面的代码所示,我们需要在 eshop 微服务的应用代码中传递 b3 HTTP Header。
@RequestMapping(value = "/checkout")
public String checkout(@RequestHeader HttpHeaders headers) {
String result = "";
// Use HTTP GET in this demo. In a real world use case,We should use HTTP POST
// instead.
// The three services are bundled in one jar for simplicity. To make it work,
// define three services in Kubernets.
result += restTemplate.exchange("http://inventory:8080/createOrder", HttpMethod.GET,
new HttpEntity<>(passTracingHeader(headers)), String.class).getBody();
result += "<BR>";
result += restTemplate.exchange("http://billing:8080/payment", HttpMethod.GET,
new HttpEntity<>(passTracingHeader(headers)), String.class).getBody();
result += "<BR>";
result += restTemplate.exchange("http://delivery:8080/arrangeDelivery", HttpMethod.GET,
new HttpEntity<>(passTracingHeader(headers)), String.class).getBody();
return result;
}
private HttpHeaders passTracingHeader(HttpHeaders headers) {
HttpHeaders tracingHeaders = new HttpHeaders();
extractHeader(headers, tracingHeaders, "x-request-id");
extractHeader(headers, tracingHeaders, "x-b3-traceid");
extractHeader(headers, tracingHeaders, "x-b3-spanid");
extractHeader(headers, tracingHeaders, "x-b3-parentspanid");
extractHeader(headers, tracingHeaders, "x-b3-sampled");
extractHeader(headers, tracingHeaders, "x-b3-flags");
extractHeader(headers, tracingHeaders, "x-ot-span-context");
return tracingHeaders;
}
下面我们来测试一下 eshop 实例程序。我们可以自己搭建一个 Kubernetes 集群并安装 Istio 以用于测试。这里为了方便,直接使用腾讯云上提供的全托管的服务网格 TCM,并在创建的 Mesh 中加入了一个容器服务 TKE 集群来进行测试。
在 TKE 集群中部署该程序,查看 Istio 分布式调用跟踪的效果。
git clone git@github.com:aeraki-framework/method-level-tracing-with-istio.git
cd method-level-tracing-with-istio
git checkout without-opentracing
kubectl apply -f k8s/eshop.yaml
- 在浏览器中打开地址:http://${INGRESS_EXTERNAL_IP}/checkout ,以触发调用 eshop 示例程序的 REST 接口。
- 在浏览器中打开 TCM 的界面,查看生成的分布式调用跟踪信息。
TCM 图形界面直观地展示了这次调用的详细信息,可以看到客户端请求从 Ingressgateway 进入到系统中,然后调用了 eshop 微服务的 checkout 接口,checkout 调用有三个 child span,分别对应到 inventory,billing 和 delivery 三个微服务的 REST 接口。

使用 OpenTracing 来传递分布式跟踪上下文
OpenTracing 提供了基于 Spring 的代码埋点,因此我们可以使用 OpenTracing Spring 框架来提供 HTTP header 的传递,以避免这部分硬编码工作。在 Spring 中采用 OpenTracing 来传递分布式跟踪上下文非常简单,只需要下述两个步骤:
- 在 Maven POM 文件中声明相关的依赖,一是对 OpenTracing Spring Cloud Starter 的依赖;另外由于 Istio 采用了 Zipkin 的上报接口,我们也需要引入 Zipkin 的相关依赖。
- 在 Spring Application 中声明一个 Tracer bean。如下所示,注意我们需要把 Istio 中的 Zipkin 上报地址设置到 OKHttpSernder 中。
@Bean
public io.opentracing.Tracer zipkinTracer() {
String zipkinEndpoint = System.getenv("ZIPKIN_ENDPOINT");
if (zipkinEndpoint == null || zipkinEndpoint == ""){
zipkinEndpoint = "http://zipkin.istio-system:9411/api/v2/spans";
}
OkHttpSender sender = OkHttpSender.create(zipkinEndpoint);
Reporter spanReporter = AsyncReporter.create(sender);
Tracing braveTracing = Tracing.newBuilder()
.localServiceName("my-service")
.propagationFactory(B3Propagation.FACTORY)
.spanReporter(spanReporter)
.build();
Tracing braveTracer = Tracing.newBuilder()
.localServiceName("spring-boot")
.spanReporter(spanReporter)
.propagationFactory(B3Propagation.FACTORY)
.traceId128Bit(true)
.sampler(Sampler.ALWAYS_SAMPLE)
.build();
return BraveTracer.create(braveTracer);
}
部署采用 OpenTracing 进行 HTTP header 传递的程序版本,其调用跟踪信息如下所示:
 从上图中可以看到,相比在应用代码中直接传递 HTTP header 的方式,采用 OpenTracing 进行代码埋点后,相同的调用增加了 7 个名称前缀为 spring-boot 的 Span,这 7 个 Span 是由 OpenTracing 的 tracer 生成的。虽然我们并没有在代码中显示创建这些 Span,但 OpenTracing 的代码埋点会自动为每一个 REST 请求生成一个 Span,并根据调用关系关联起来。
从上图中可以看到,相比在应用代码中直接传递 HTTP header 的方式,采用 OpenTracing 进行代码埋点后,相同的调用增加了 7 个名称前缀为 spring-boot 的 Span,这 7 个 Span 是由 OpenTracing 的 tracer 生成的。虽然我们并没有在代码中显示创建这些 Span,但 OpenTracing 的代码埋点会自动为每一个 REST 请求生成一个 Span,并根据调用关系关联起来。
OpenTracing 生成的这些 Span 为我们提供了更详细的分布式调用跟踪信息,从这些信息中可以分析出一个 HTTP 调用从客户端应用代码发起请求,到经过客户端的 Envoy,再到服务端的 Envoy,最后到服务端接受到请求各个步骤的耗时情况。从图中可以看到,Envoy 转发的耗时在 1 毫秒左右,相对于业务代码的处理时长非常短,对这个应用而言,Envoy 的处理和转发对于业务请求的处理效率基本没有影响。
在 Istio 调用跟踪链中加入方法级的调用跟踪信息
Istio/Envoy 提供了跨服务边界的调用链信息,在大部分情况下,服务粒度的调用链信息对于系统性能和故障分析已经足够。但对于某些服务,需要采用更细粒度的调用信息来进行分析,例如一个 REST 请求内部的业务逻辑和数据库访问分别的耗时情况。在这种情况下,我们需要在服务代码中进行埋点,并将服务代码中上报的调用跟踪数据和 Envoy 生成的调用跟踪数据进行关联,以统一呈现 Envoy 和服务代码中生成的调用数据。
在方法中增加调用跟踪的代码是类似的,因此我们用 AOP + Annotation 的方式实现,以简化代码。
首先定义一个 Traced 注解和对应的 AOP 实现逻辑:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Documented
public @interface Traced {
}
@Aspect
@Component
public class TracingAspect {
@Autowired
Tracer tracer;
@Around("@annotation(com.zhaohuabing.demo.instrument.Traced)")
public Object aroundAdvice(ProceedingJoinPoint jp) throws Throwable {
String class_name = jp.getTarget().getClass().getName();
String method_name = jp.getSignature().getName();
Span span = tracer.buildSpan(class_name + "." + method_name).withTag("class", class_name)
.withTag("method", method_name).start();
Object result = jp.proceed();
span.finish();
return result;
}
}
然后在需要进行调用跟踪的方法上加上 Traced 注解:
@Component
public class DBAccess {
@Traced
public void save2db() {
try {
Thread.sleep((long) (Math.random() * 100));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
@Component
public class BankTransaction {
@Traced
public void transfer() {
try {
Thread.sleep((long) (Math.random() * 100));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
demo 程序的 master branch 已经加入了方法级代码跟踪,可以直接部署。
git checkout master
kubectl apply -f k8s/eshop.yaml
效果如下图所示,可以看到 trace 中增加了 transfer 和 save2db 两个方法级的 Span。
 可以打开一个方法的 Span,查看详细信息,包括 Java 类名和调用的方法名等,在 AOP 代码中还可以根据需要添加出现异常时的异常堆栈等信息。
可以打开一个方法的 Span,查看详细信息,包括 Java 类名和调用的方法名等,在 AOP 代码中还可以根据需要添加出现异常时的异常堆栈等信息。

总结
Istio/Envoy 为微服务应用提供了分布式调用跟踪功能,提高了服务调用的可见性。我们可以使用 OpenTracing 来代替应用硬编码,以传递分布式跟踪的相关 http header;还可以通过 OpenTracing 将方法级的调用信息加入到 Istio/Envoy 缺省提供的调用链跟踪信息中,以提供更细粒度的调用跟踪信息。
下一步
除了同步调用之外,异步消息也是微服务架构中常见的一种通信方式。在下一篇文章中,我将继续利用 eshop demo 程序来探讨如何通过 OpenTracing 将 Kafka 异步消息也纳入到 Istio 的分布式调用跟踪中。
参考资料
- 本文中 eshop 示例程序的源代码
- Opentracing docs
- Opentracing specification
- Opentracing wire protocols
- Istio Trace context propagation
- Zipkin-b3-propagation
- OpenTracing Project Deep Dive
3.5 - 在 Istio 中实现异步消息调用跟踪
在实际项目中,除了同步调用之外,异步消息也是微服务架构中常见的一种通信方式。在本篇文章中,我将继续利用 eshop demo 程序来探讨如何通过 OpenTracing 将 Kafka 异步消息也纳入到 Istio 的分布式调用跟踪中。
eshop 示例程序结构
如下图所示,demo 程序中增加了发送和接收 Kafka 消息的代码。eshop 微服务在调用 inventory,billing,delivery 服务后,发送了一个 kafka 消息通知,consumer 接收到通知后调用 notification 服务的 REST 接口向用户发送购买成功的邮件通知。

将 Kafka 消息处理加入调用链跟踪
植入 Kafka OpenTracing 代码
首先从 github 下载代码。
git clone git@github.com:aeraki-framework/method-level-tracing-with-istio.git
可以直接使用该代码,但建议跟随下面的步骤查看相关的代码,以了解各个步骤背后的原理。
根目录下分为了 rest-service 和 kafka-consumer 两个目录,rest-service 下包含了各个 REST 服务的代码,kafka-consumer 下是 Kafka 消息消费者的代码。
首先需要将 spring kafka 和 OpenTracing kafka 的依赖加入到两个目录下的 pom 文件中。
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>io.opentracing.contrib</groupId>
<artifactId>opentracing-kafka-client</artifactId>
<version>${version.opentracing.kafka-client}</version>
</dependency>
在 rest-service 目录中的 KafkaConfig.java 中配置消息 Producer 端的 OpenTracing Instrument。TracingProducerInterceptor 会在发送 Kafka 消息时生成发送端的 Span。
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress);
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, TracingProducerInterceptor.class.getName());
return new DefaultKafkaProducerFactory<>(configProps);
}
在 kafka-consumer 目录中的 KafkaConfig.java 中配置消息 Consumer 端的 OpenTracing Instrument。TracingConsumerInterceptor 会在接收到 Kafka 消息是生成接收端的 Span。
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, TracingConsumerInterceptor.class.getName());
return new DefaultKafkaConsumerFactory<>(props);
}
只需要这两步即可完成 Spring 程序的 Kafka OpenTracing 代码植入。下面安装并运行示例程序查看效果。
安装 Kafka 集群
示例程序中使用到了 Kafka 消息,因此我们在 TKE 集群中部署一个简单的 Kafka 实例:
cd method-level-tracing-with-istio
kubectl apply -f k8s/kafka.yaml
部署 demo 应用
修改 Kubernetes yaml 部署文件 k8s/eshop.yaml,设置 Kafka bootstrap server,以用于 demo 程序连接到 Kafka 集群中。
apiVersion: apps/v1
kind: Deployment
metadata:
name: delivery
......
spec:
containers:
- name: eshop
image: aeraki/istio-opentracing-demo:latest
ports:
- containerPort: 8080
env:
....
//在这里加入 Kafka server 地址
- name: KAFKA_BOOTSTRAP_SERVERS
value: "kafka-service:9092"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-consumer
......
spec:
containers:
- name: kafka-consumer
image: aeraki/istio-opentracing-demo-kafka-consumer:latest
env:
....
//在这里加入 Kafka server 地址
- name: KAFKA_BOOTSTRAP_SERVERS
value: "kafka-service:9092"
然后部署应用程序,相关的镜像可以直接从 dockerhub 下载,也可以通过源码编译生成。
kubectl apply -f k8s/eshop.yaml
在浏览器中打开地址:http://${INGRESS_EXTERNAL_IP}/checkout ,以触发调用 eshop 示例程序的 REST 接口。然后打开 TCM 的界面查看生成的分布式调用跟踪信息。

从图中可以看到,在调用链中增加了两个 Span,分布对应于Kafka消息发送和接收的两个操作。由于Kafka消息的处理是异步的,消息发送端不直接依赖接收端的处理。根据 OpenTracing 对引用关系的定义,From_eshop_topic Span 对 To_eshop_topic Span 的引用关系是 FOLLOWS_FROM 而不是 CHILD_OF 关系。
将调用跟踪上下文从Kafka传递到REST服务
现在 eshop 代码中已经加入了 REST 和 Kafka 的 OpenTracing Instrumentation,可以在进行 REST 调用和发送 Kafka 消息时生成调用跟踪信息。但如果需要从 Kafka 的消息消费者的处理方法中调用一个 REST 接口呢?
我们会发现在 eshop 示例程序中,缺省生成的调用链里面并不会把 Kafka 消费者的 Span 和其发起的调用 notification 服务的 REST 请求的 Span 关联在同一个 Trace 中。
要分析导致该问题的原因,我们首先需要了解“Active Span”的概念。在 OpenTracing 中,一个线程可以有一个 Active Span,该 Active Span 代表了目前该线程正在执行的工作。在调用 Tracer.buildSpan() 方法创建新的 Span 时,如果 Tracer 目前存在一个 Active Span,则会将该 Active Span 缺省作为新创建的 Span 的 Parent Span。
Tracer.buildSpan 方法的说明如下:
Tracer.SpanBuilder buildSpan(String operationName)
Return a new SpanBuilder for a Span with the given `operationName`.
You can override the operationName later via BaseSpan.setOperationName(String).
A contrived example:
Tracer tracer = ...
// Note: if there is a `tracer.activeSpan()`, it will be used as the target of an implicit CHILD_OF
// Reference for "workSpan" when `startActive()` is invoked.
// 如果存在 active span,则其创建的新 Span 会隐式地创建一个 CHILD_OF 引用到该 active span
try (ActiveSpan workSpan = tracer.buildSpan("DoWork").startActive()) {
workSpan.setTag("...", "...");
// etc, etc
}
// 也可以通过 asChildOf 方法指定新创建的 Span 的 Parent Span
// It's also possible to create Spans manually, bypassing the ActiveSpanSource activation.
Span http = tracer.buildSpan("HandleHTTPRequest")
.asChildOf(rpcSpanContext) // an explicit parent
.withTag("user_agent", req.UserAgent)
.withTag("lucky_number", 42)
.startManual();
分析 Kafka OpenTracing Instrumentation 的代码,会发现 TracingConsumerInterceptor 在调用 Kafka 消费者的处理方法之前已经把消费者的 Span 结束了,因此发起 REST 调用时 tracer 没有 active span,不会将 Kafka 消费者的 Span 作为后面 REST 调用的 parent span。
public static <K, V> void buildAndFinishChildSpan(ConsumerRecord<K, V> record, Tracer tracer,
BiFunction<String, ConsumerRecord, String> consumerSpanNameProvider) {
SpanContext parentContext = TracingKafkaUtils.extractSpanContext(record.headers(), tracer);
String consumerOper =
FROM_PREFIX + record.topic(); // <====== It provides better readability in the UI
Tracer.SpanBuilder spanBuilder = tracer
.buildSpan(consumerSpanNameProvider.apply(consumerOper, record))
.withTag(Tags.SPAN_KIND.getKey(), Tags.SPAN_KIND_CONSUMER);
if (parentContext != null) {
spanBuilder.addReference(References.FOLLOWS_FROM, parentContext);
}
Span span = spanBuilder.start();
SpanDecorator.onResponse(record, span);
//在调用消费者的处理方法之前,该 Span 已经被结束。
span.finish();
// Inject created span context into record headers for extraction by client to continue span chain
//这个 Span 被放到了 Kafka 消息的 header 中
TracingKafkaUtils.inject(span.context(), record.headers(), tracer);
}
此时 TracingConsumerInterceptor 已经将 Kafka 消费者的 Span 放到了 Kafka 消息的 header 中,因此从 Kafka 消息头中取出该 Span,显示地将 Kafka 消费者的 Span 作为 REST 调用的 Parent Span 即可。
为MessageConsumer.java使用的RestTemplate设置一个TracingKafka2RestTemplateInterceptor。
@KafkaListener(topics = "eshop-topic")
public void receiveMessage(ConsumerRecord<String, String> record) {
restTemplate
.setInterceptors(Collections.singletonList(new TracingKafka2RestTemplateInterceptor(record.headers())));
restTemplate.getForEntity("http://notification:8080/sendEmail", String.class);
}
TracingKafka2RestTemplateInterceptor 是基于 Spring OpenTracing Instrumentation 的 TracingRestTemplateInterceptor 修改的,将从 Kafka header 中取出的 Span 设置为出向请求的 Span 的 Parent Span。
@Override
public ClientHttpResponse intercept(HttpRequest httpRequest, byte[] body, ClientHttpRequestExecution xecution)
throws IOException {
ClientHttpResponse httpResponse;
SpanContext parentSpanContext = TracingKafkaUtils.extractSpanContext(headers, tracer);
Span span = tracer.buildSpan(httpRequest.getMethod().toString()).asChildOf(parentSpanContext)
.withTag(Tags.SPAN_KIND.getKey(), Tags.SPAN_KIND_CLIENT).start();
......
}
在浏览器中打开地址:http://${INGRESS_EXTERNAL_IP}/checkout ,以触发调用 eshop 示例程序的 REST 接口。然后打开 TCM 的界面查看生成的分布式调用跟踪信息。
从上图可以看到,调用链中出现了 Kafka 消费者调用 notification 服务的 sendEmail REST 接口的 Span。从图中可以看到,由于调用链经过了 Kafka 消息,sendEmail Span 的时间没有包含在 checkout Span 中。
总结
Istio 服务网格通过分布式调用跟踪来提高微服务应用的可见性,这需要在应用程序中通过 HTTP header 传递调用跟踪的上下文。对于 JAVA 应用程序,我们可以使用 OpenTracing Instrumentation 来代替应用编码传递分布式跟踪的相关 http header,以减少对业务代码的影响;我们还可以将方法级的调用跟踪和 Kafka 消息的调用跟踪加入到 Istio 生成的调用跟踪链中,以为应用程序的故障定位提供更为丰富详细的调用跟踪信息。
参考资料
- 本文中 eshop 示例程序的源代码
4 - TCM 介绍
腾讯云 TCM 介绍
TCM(Tencent Cloud Mesh)是腾讯云上提供的基于 Istio 进行增强,和 Istio API 完全兼容的 Service Mesh 托管服务,集成腾讯云基础设施,提供全托管服务化的支撑能力保障网格生命周期管理。可以帮助用户以较小的迁移成本和维护代价快速利用到 Service Mesh 提供的流量管理和服务治理能力。
体验 TCM